

https://arxiv.org/html/2507.04786v1
Introduction
-
Goal: train a model.
-
What is training?
- Transformers. Attention is all you need.
- Transformers are just a bunch of matmuls.
- What’s good at matmuls? GPUs!
-
Why are GPUs good at matmuls? https://www.modular.com/blog/matrix-multiplication-on-nvidias-blackwell-part-1-introduction
- Matmuls of large matrices can be decomposed into smaller matmul operations, then reduced into
- GPUs have a a bunch of hardware that is specifically optimized for tiled matmuls (tensor cores) and a bunch of hardware that makes them work well together (registers, shared memory, caches, high-bandwidth buses).
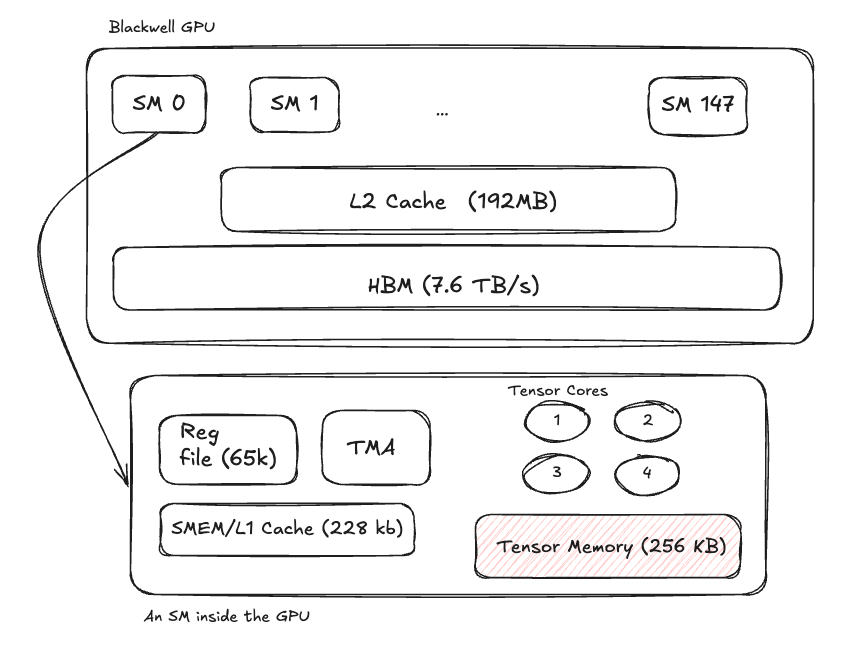
- Streaming Multiprocessors (SMs) coordinate scheduling and information flow between the GPU’s central control plane and individual tensor units.
-
Training a model with one GPU is slow. (why?)
- You can’t fit that much data into VRAM at one time, so you get heavily bottlenecked by dataloading.
- There just aren’t enough tensor cores to do all the matmuls you can possibly do. (Training is so parallelizable; throwing more compute at the problem makes it nearly linearly faster…)
-
How do we train on multiple GPUs?
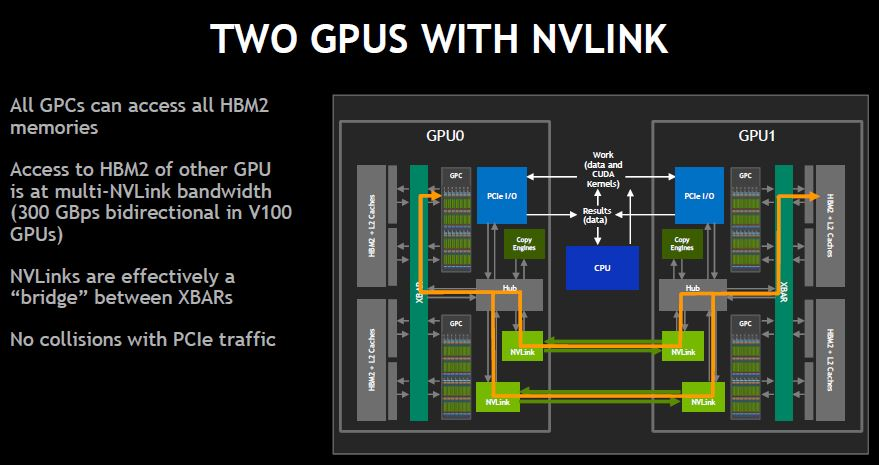 - A single computer (node) usually can host up to 8 individual GPUs on the same motherboard etc. - the GPUs are connected via NVLink, which allows separate GPUs to talk to each other at 50GB/s (per link) over PCIe and effectively share a single, large VRAM pool.
- A single computer (node) usually can host up to 8 individual GPUs on the same motherboard etc. - the GPUs are connected via NVLink, which allows separate GPUs to talk to each other at 50GB/s (per link) over PCIe and effectively share a single, large VRAM pool. -
Great, what if I want more than 8 GPUs??
- Connect multiple nodes together on the internet.
- Use Infiniband RDMA (remote direct memory access).
- Specialized protocol + networking hardware that allows for faster + lower-latency communication compared to standard ethernet.
-
So, how do I matmul on like 1000 gpus if they don’t all share a single control plane??
- This is where NCCL (NVIDIA Collective Communication Library) comes in, which allows GPUs to share a common communication language to persist
NCCL
Channels
The main abstraction in NCCL is the channel. Each channel is bound to a single SM in a GPU.
Each chunk of memory in the buffer (see Protocols) is subdivided by the number of channels that are available to process it.
Protocols
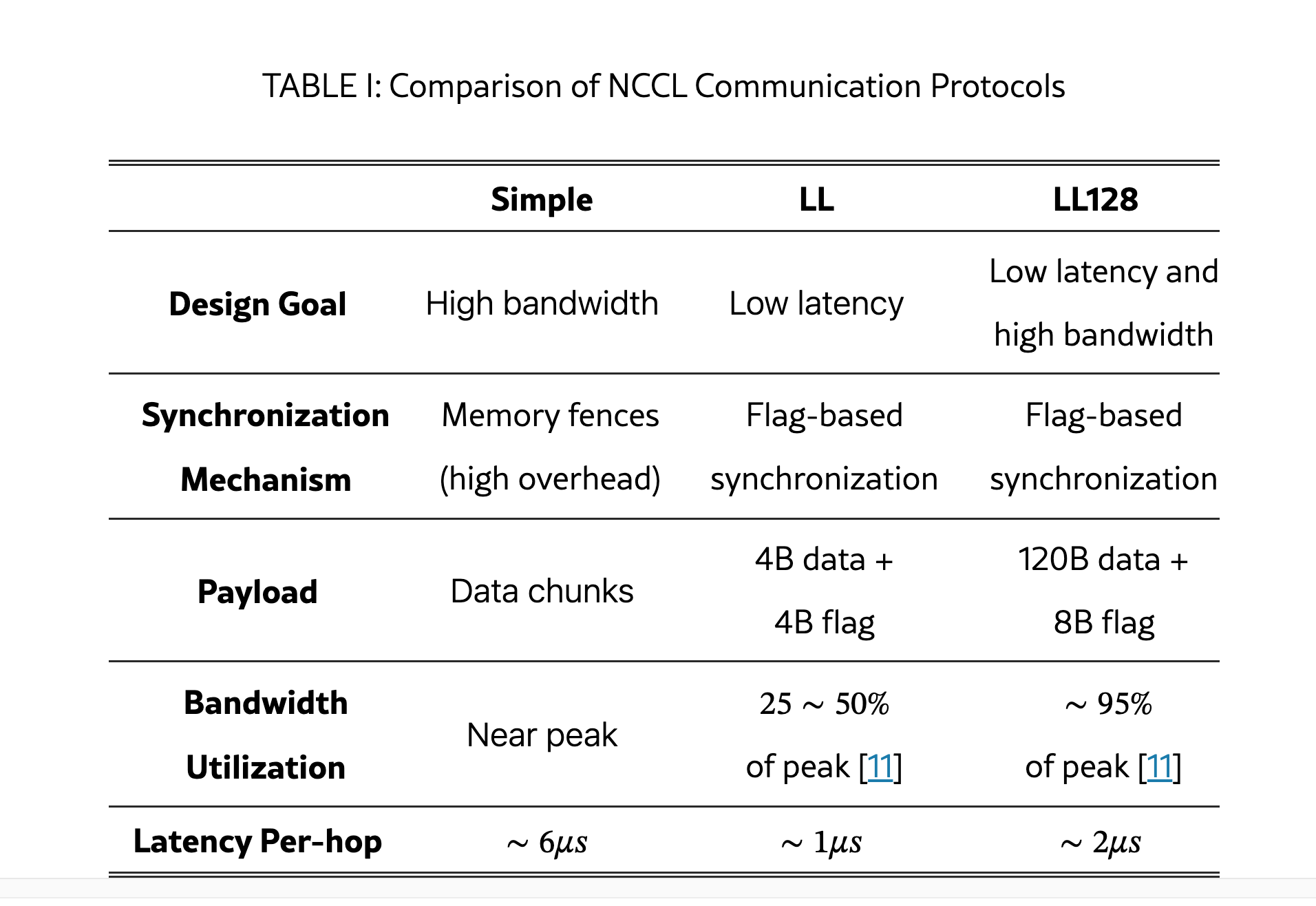
Simple: Sends large data chunks with memory fences. Designed to saturate bandwidth (at the cost of high latency for smaller messages, since there isn’t enough data to fill the buffer).
LL (Low Latency): significantly reduces latency by chunking into smaller (8-byte) atomic writes, but at the cost of reduced bandwidth. Good for message sizes <64KB.
LL128: Uses 128-byte aligned atomic writes to strike a balance between latency and bandwidth (can reach up to 95% max bandwidth). Requires specialized hardware over NVlink.
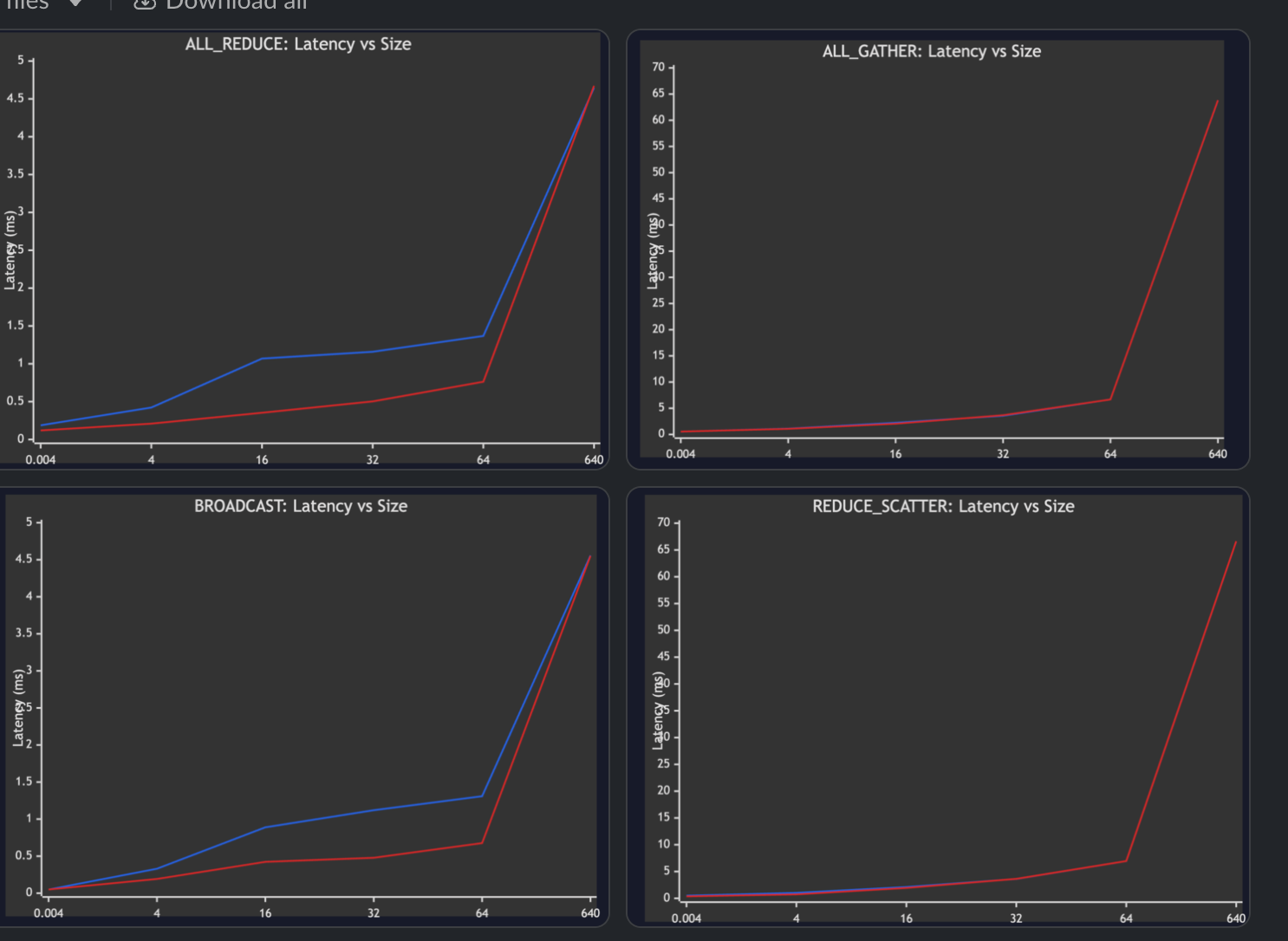
I ran a benchmark on our H100 cluster and LL128 is indeed noticeably faster than Simple for small/medium message sizes! (red line is LL128; lower latency is better)
Operations
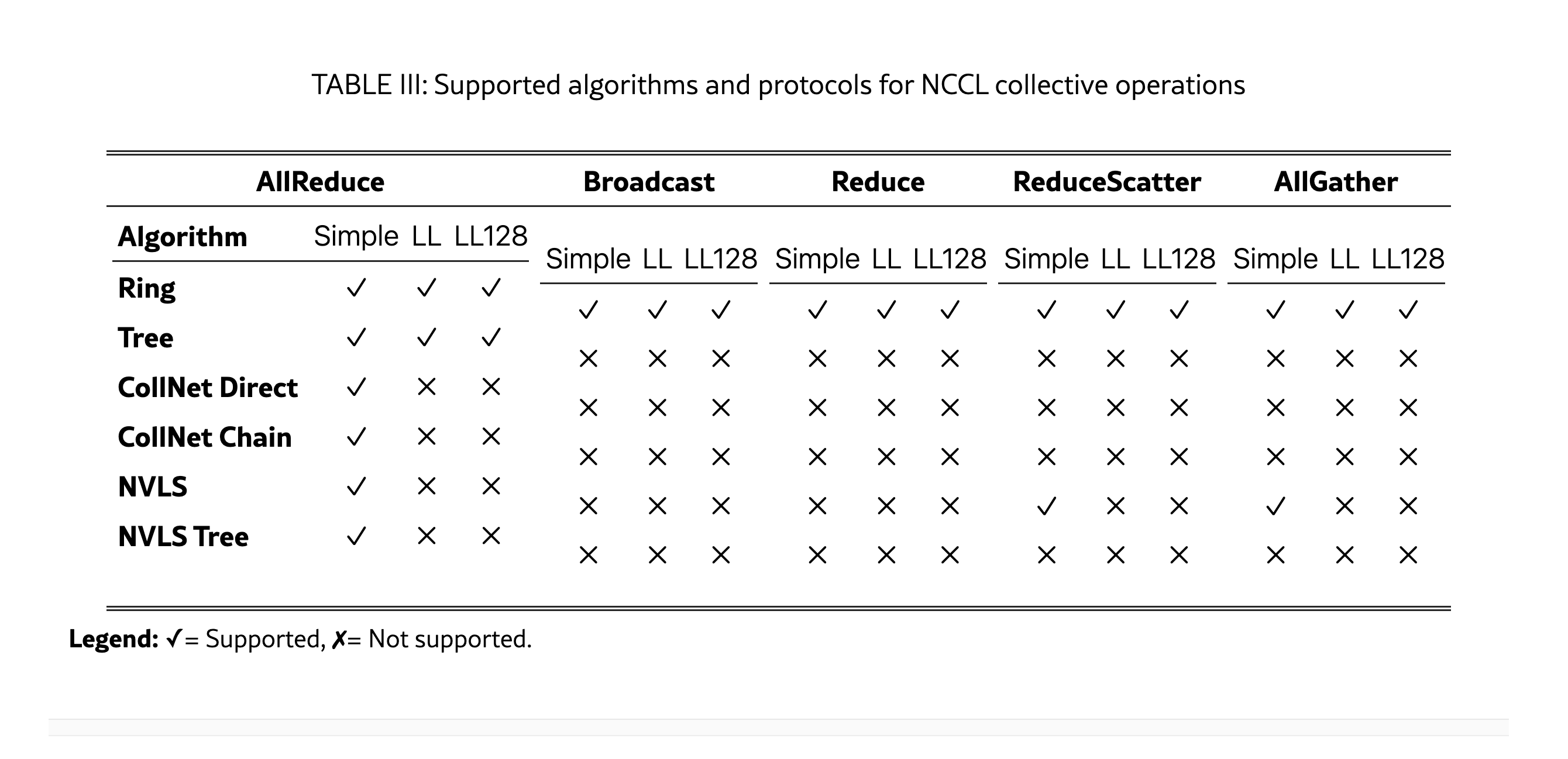
NCCL supports 5 collective operations (AllReduce, Broadcast, Reduce, AllGather, ReduceScatter) and two point-to-point operations (Send, Recv).
According to Gemini this is what each NCCL operation is used for. I’ll write a real note for this when I get a chance (the question of “why do we need collective communication” is an important prerequisite to answer).
| NCCL Operation | Role in Model Training / Matrix Multiplication | Distributed Training Step |
|---|---|---|
| AllReduce | The most critical operation. It efficiently computes the sum (or average) of gradients across all GPUs and returns the identical, aggregated result to every single GPU. | Gradient Synchronization / Backpropagation: Used to aggregate the gradients calculated locally by each GPU’s batch of data. After the AllReduce, all GPUs have the synchronized new average gradient, ready for the optimizer step. |
| Broadcast | Copies a data buffer from one “root” GPU to all other GPUs. | Initial Model Setup & Updates: Used once at the beginning of training to share the initial model weights from a root GPU to all workers. It can also be used in an alternative approach where one GPU performs the parameter update and broadcasts the new model parameters to everyone else. |
| Reduce | Performs a reduction (e.g., sum, min, max) of data across all GPUs, but stores the result only on a specified “root” GPU. | Alternative Aggregation/Diagnostics: Used when only one GPU needs the final result, such as when gathering a summary statistic or aggregating gradients before a central parameter server applies the update. (Note: ). |
| ReduceScatter | Combines reduction with scattering. The input from all GPUs is reduced, and the resulting data is split into equal-sized blocks and scattered to the GPUs, with each receiving one part. | Efficient AllReduce Implementation / Model Parallelism: It’s the first half of a two-step (). It’s also used in advanced techniques like Fully Sharded Data Parallelism (FSDP) for scattering gradients. |
| AllGather | Gathers the entire set of local data from all GPUs and then distributes the concatenated result (in rank order) back to all GPUs. | Model Parallelism / State Synchronization: It is the second half of the efficient two-step . In FSDP, it’s used to collect sharded model parameters (FSDP unit parameters) onto each GPU during the forward and backward passes. |
Ring AllReduce
In the ring algorithm, GPUs are arranged in a circular fashion (so each GPU knows which one comes before and after it). Messages are sent unidirectionally until they all reach their intended destinations.
For an AllReduce operation, this involves two phases:
- ReduceScatter: Each GPU reduces its local data with received data and keeps a specific segment.
- AllGather: Each GPU then forwards its segment to all others. This algorithm requires 2(k–1) steps for k GPUs. Each channel executes a sequence of pipelined steps (like recvReduceSend or recvCopySend) within its buffer slots, intelligently overlapping network and compute operations.

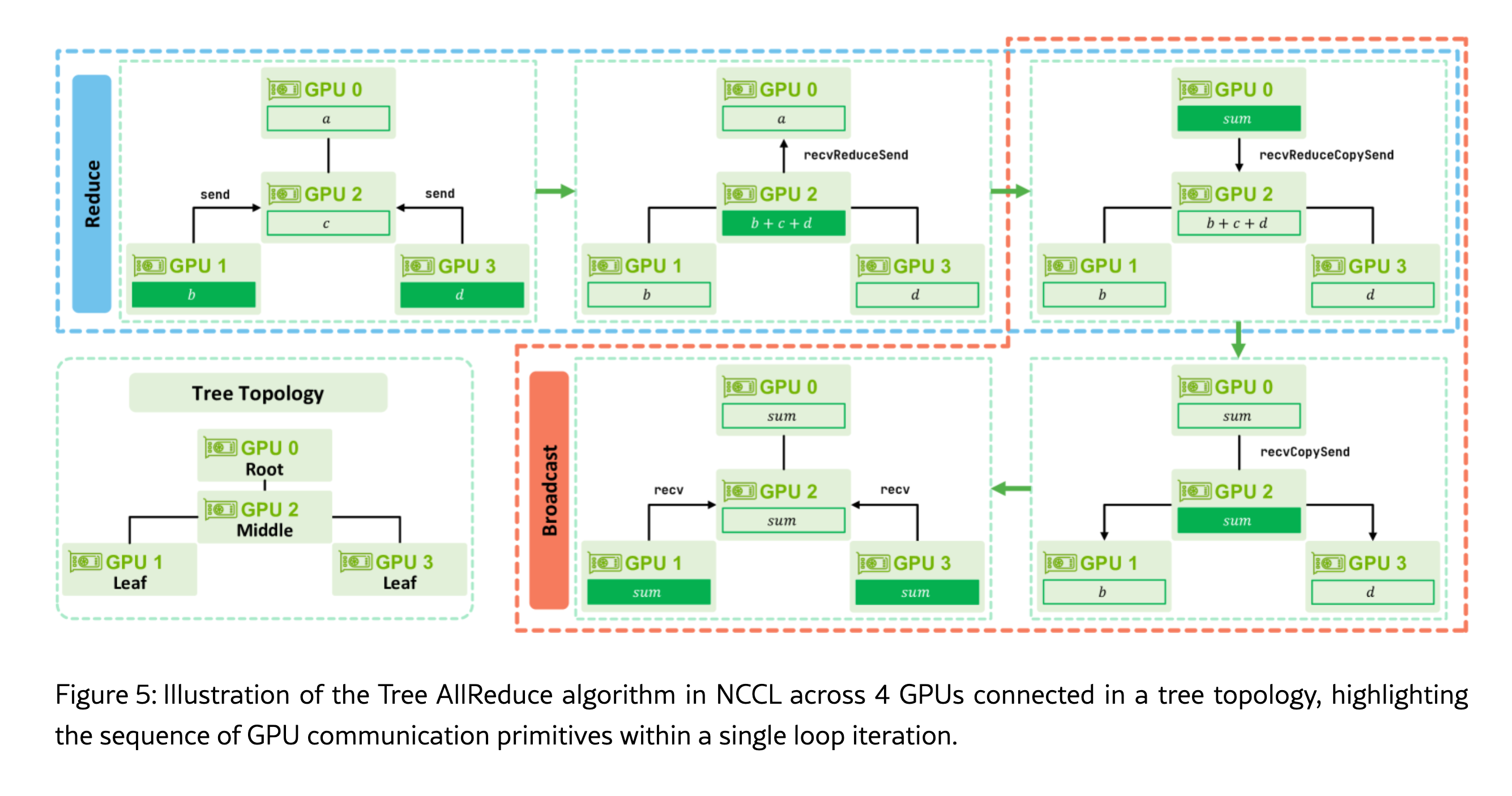
Tree AllReduce
If you have hundreds/thousands of GPUs, putting them all into one big ring would be really inefficient.
The Tree Algorithm organizes GPUs into a binary tree-like structure where GPUs have parent GPUs and child GPUs. One GPU is elected to be the root.
- Reduce Phase (Aggregation Up): Data moves up a tree-like hierarchy towards the root GPU. Leaf GPUs initiate the data movement (), while Middle GPUs combine incoming data with local data and forward the result using a primitive. The Root GPU completes the final aggregation ().
- Broadcast Phase (Distribution Down): The fully aggregated result is then sent back down the tree. The Root sends the result to its children, and Middle GPUs continuously relay the result while saving a copy locally, using the primitive. Finally, the Leaf GPUs receive the final data (). For efficiency, these two phases can execute concurrently by dedicating more resources to the reduction step.
NCCL optimizes this by partitioning the SM’s into two groups. One group handles the reduction toward the root, while the other simultaneously performs the broadcast from the root.
Intra-node Data Transfer
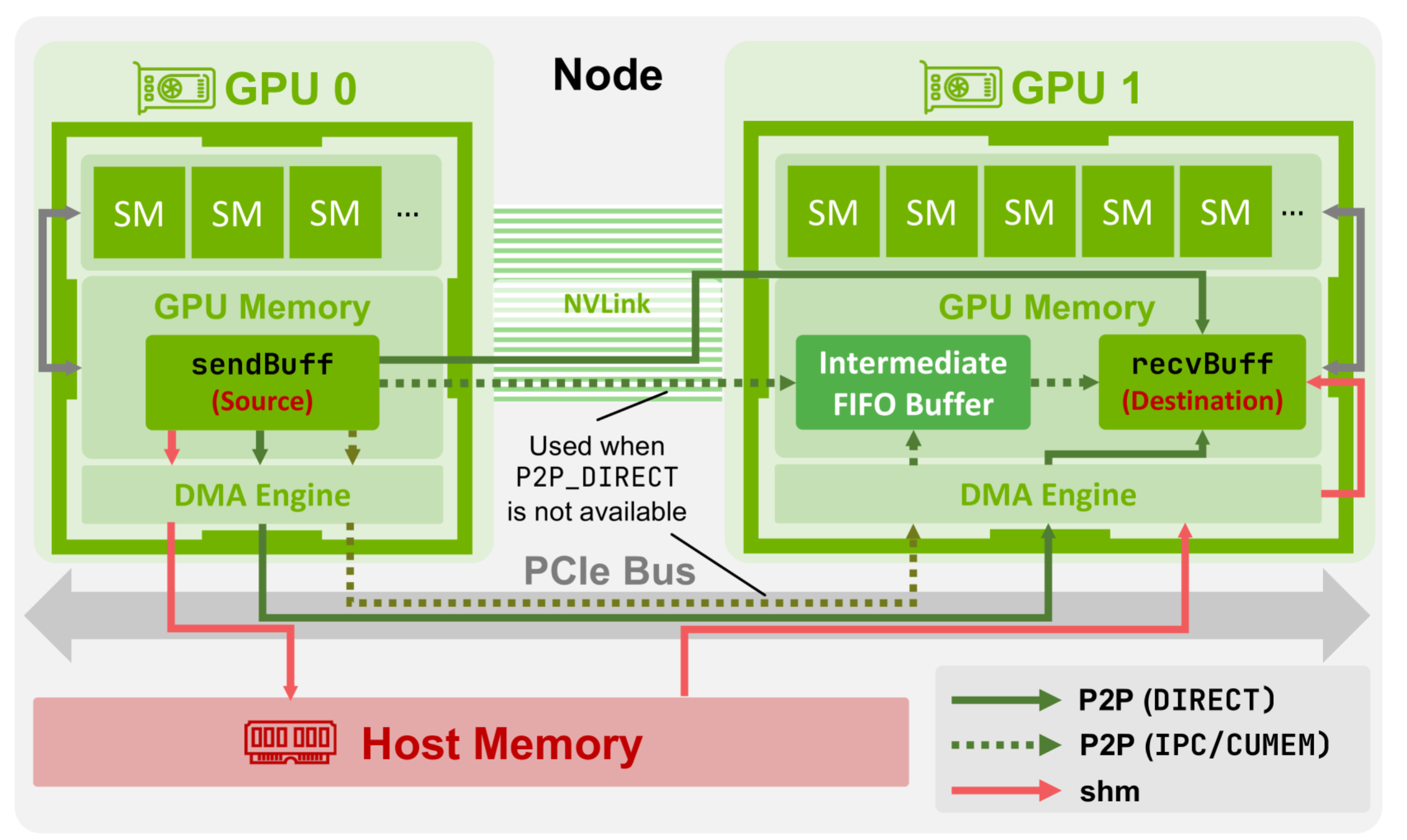
How GPUs on the same node communicate with each other.
Inter-node Data Transfer
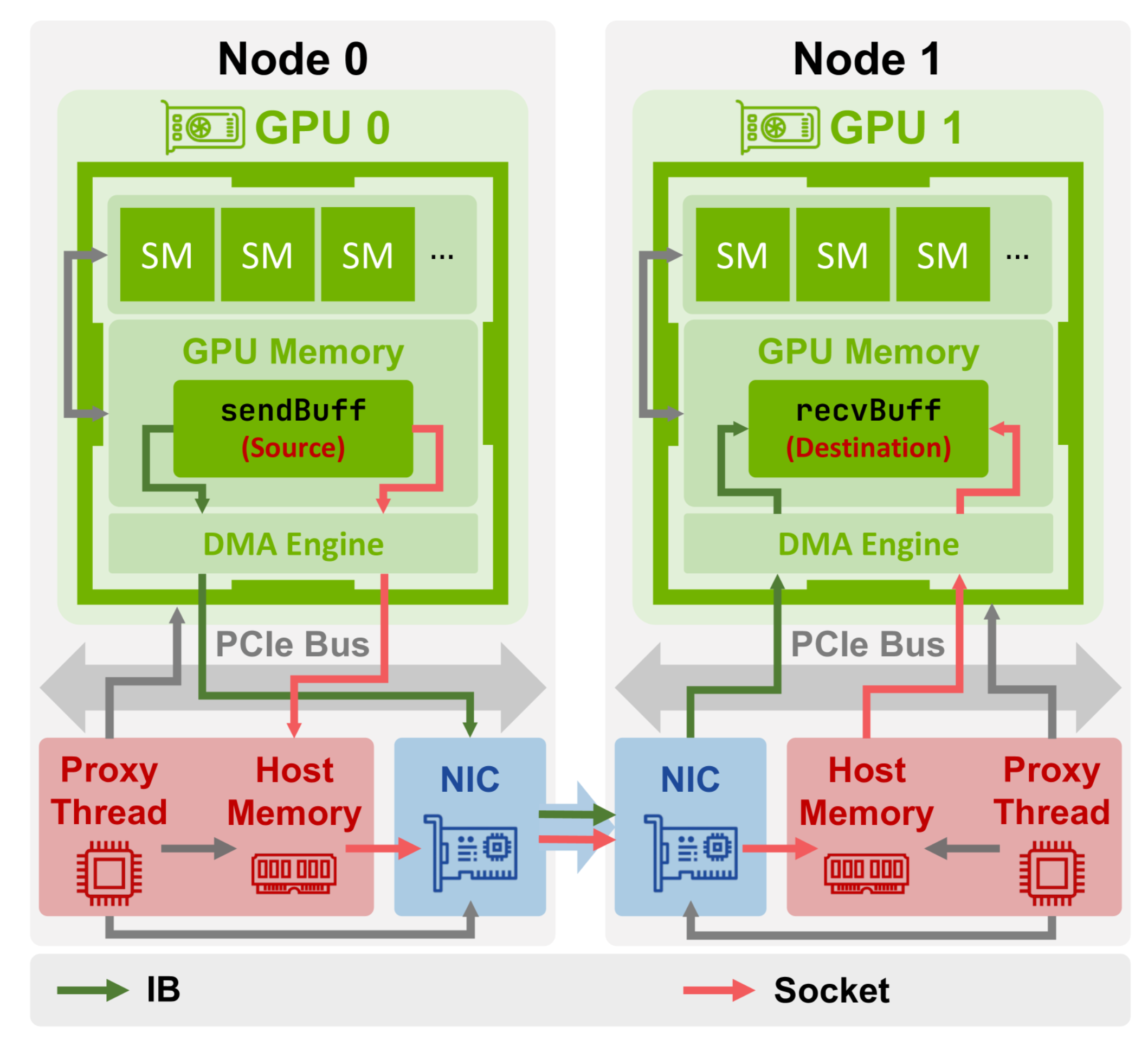
How GPUs on different nodes communicate with each other.