

 evergreen
evergreen I gave a talk at Google Cloud Next 2026! Here is the recording:
Below is a written version.
AI-generated content
This transcript was originally auto-generated by YouTube. I then cleaned it up and attached slide screenshots with the help of Claude Opus 4.7.
Introduction
This post is about Reve’s ML infrastructure. Specifically, I walk through how we built a platform around Kubernetes, Ray, and Google Cloud that handles the unique challenges of heterogeneity in ML workloads.
When designing our infrastructure, there are three main characteristics we have to consider.
First, ML workloads — especially for training — often require really high throughput and low latency communication across thousands of accelerators (GPUs or TPUs). Workloads are also parallelizable across multiple dimensions: data parallelism, tensor parallelism, pipeline parallelism, and others, all at the same time, so that we can horizontally scale almost indefinitely.
Second, we have to make our infrastructure both user-friendly to our research team as well as to millions of users who need to run inference tasks on our models.
Third, there are multiple classes of workloads that we need to consider simultaneously. I’ve classified them into four main buckets:
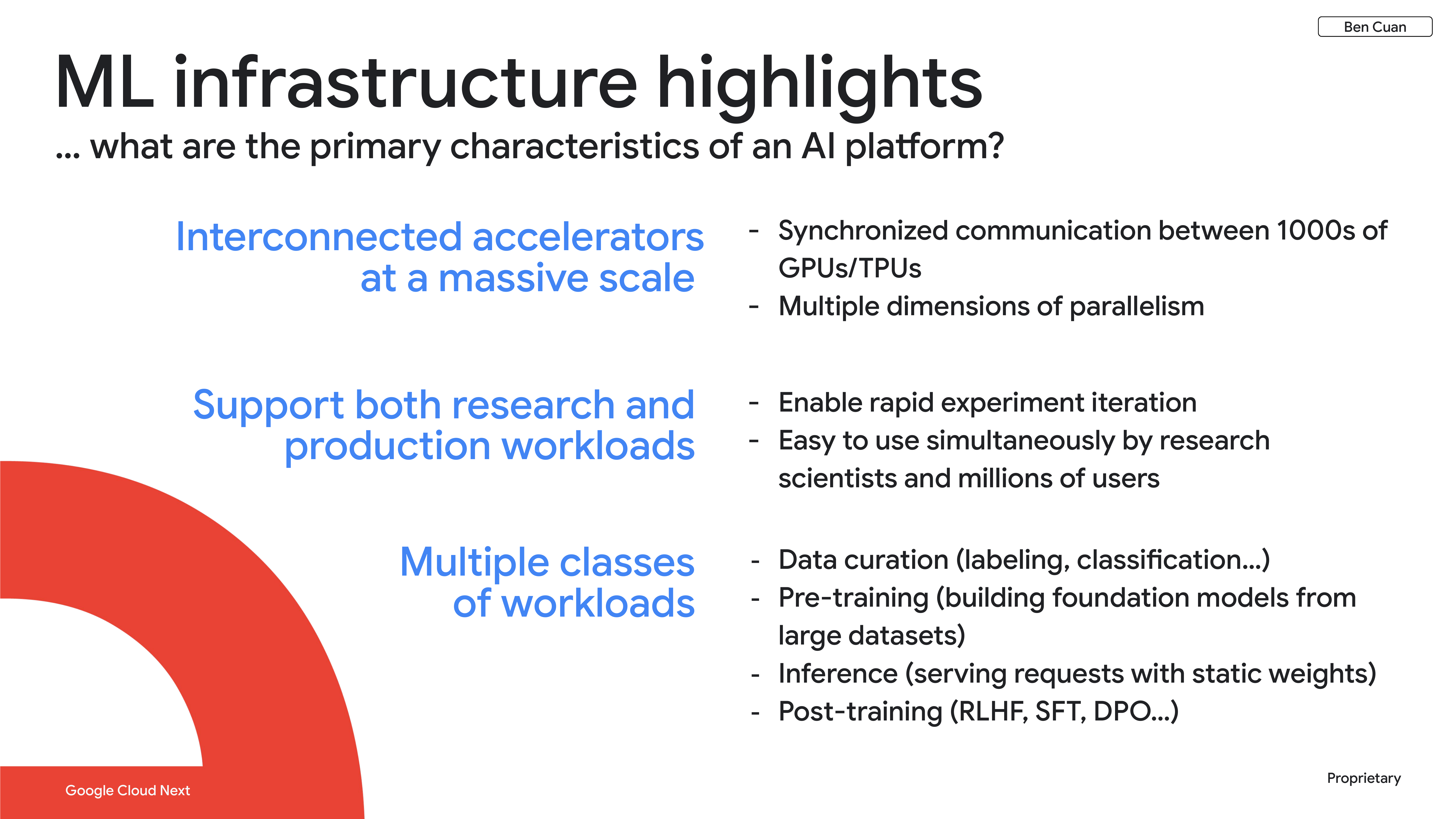
- Data curation — labeling or classifying our initial data set.
- Pre-training — building our foundation models from scratch.
- Inference — serving requests from users with the static weights that we get from pre-training.
- Post-training — techniques such as reinforcement learning with human feedback (RLHF), supervised fine-tuning (SFT), and direct preference optimization (DPO), which allow us to further customize and tune our outputs.
To support these workloads, we use two primary platforms at the core of our infrastructure stack. The first is Kubernetes, which solves the problem of orchestration — organizing thousands of individual machines into a single addressable cluster. The second is Ray, which translates machine learning workloads into something that Kubernetes can understand. We use the KubeRay operator specifically to get Kubernetes custom resources from Ray abstractions.

The main problem we’re trying to solve with these platforms is heterogeneity: our workloads vary across three main dimensions — compute, space, and time.
- Compute heterogeneity refers to workloads that need several different types of hardware all at the same time. For example, workloads often require CPU paired with GPU or TPU simultaneously.
- Temporal heterogeneity means that within a single training run, we often combine tasks that take less than a millisecond each with tasks that could take seconds or up to a minute in a codependent manner.
- Spatial heterogeneity arises because accelerators are scarce, so we need to get what we can get — and therefore they’re often spread across multiple cloud providers and geographic regions.
Compute Heterogeneity
Acquiring compute
The first problem you run into when trying to train a model is: how do you actually get the compute you need? Right now, there are three popular approaches:
- Spot instances — the easiest and most affordable way to get compute. You go to a cloud provider and say, “Give me whatever you have at the moment and I’ll pay the market price.” This is a great entry point, but it’s really hard to get reliable and collocated blocks at the scale needed for training.
- Building a data center — the opposite extreme, but this comes with a lot of problems: it’s difficult, expensive, and time-consuming.
- Reservations — the middle ground that we use at Reve. With a reservation from Google Cloud, we lease a dedicated compute block for a longer time scale such as a month or a year. This strikes the balance between availability and guaranteed uptime, giving us a dedicated amount of compute without our training runs getting interrupted.
GKE and KubeRay
Usually the next step after acquiring compute is to install Kubernetes and maintain it. This is one of the things that GKE does really well for us — it abstracts away operational concerns for Kubernetes so we can just focus on running our workloads.
Once we have a Kubernetes cluster, the next stage is to install KubeRay. The way KubeRay works is that it translates Python — which is easy to write and understand for researchers — into Kubernetes custom resources, which are easy for the infrastructure team to maintain.
Label-Based Scheduling
Ray helps us abstract away the major architectural differences between different types of hardware. To illustrate, the Hopper architecture (A3 Mega, A3 Ultra) looks completely different from Blackwell (A4 platform), but our researchers don’t need to worry about that.
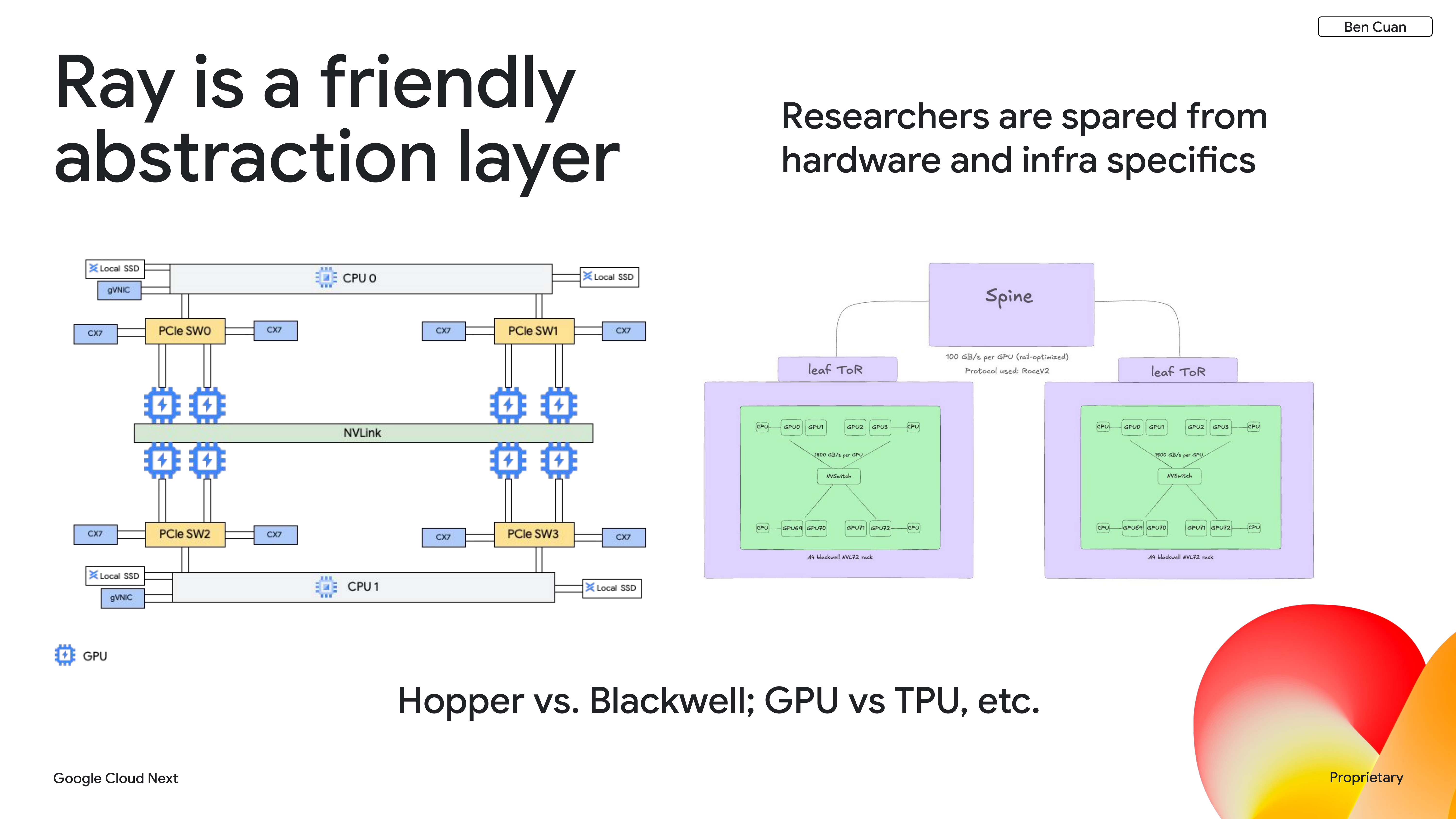
The software feature that allows us to handle this is label-based scheduling. We have a Python decorator where our research team or developers can simply choose a specific accelerator type like H100, and that gets translated into the Kubernetes world automatically.
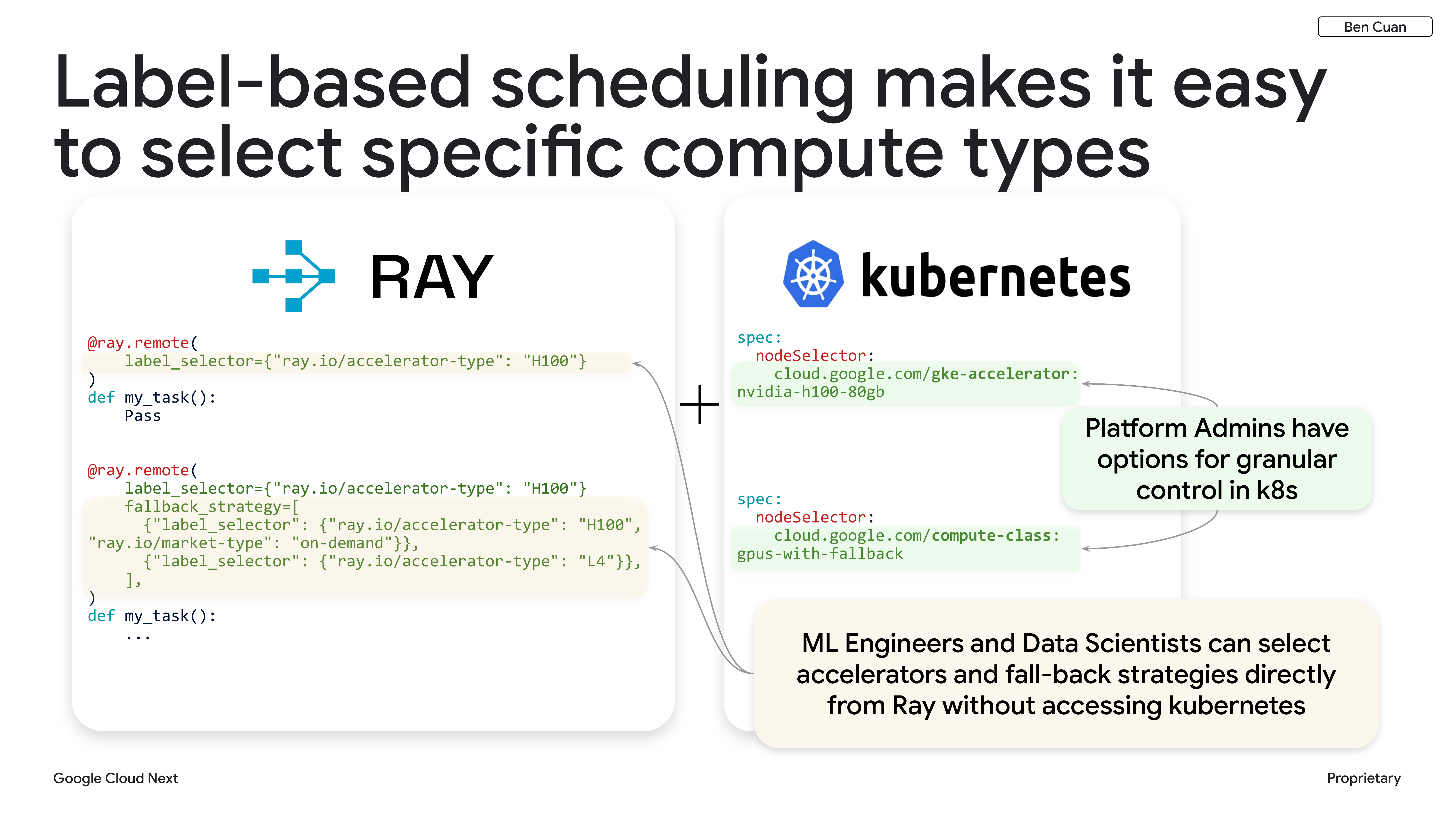
Researchers can now easily select compute types without needing to mess around with the insides of Kubernetes YAML. The high-level goal is to be as flexible as possible for future compute platforms. Right now at Reve, we’re primarily on the Hopper GPU architecture with PyTorch. In the future, we expect that to change as things get more optimized — for example, we’re looking into GB200s, the future Vera Rubin platform, as well as TPUs.
Temporal Heterogeneity
Idle compute is expensive
The crux of temporal heterogeneity is that idle compute is expensive. We have a reservation, which means that whether or not we’re actually using our allocation for running useful workloads, we’re still paying for it. Ideally, our accelerators are working 100% of the time, but this is hard for a few reasons:
- Bottlenecks constantly shift across different parts of our training pipeline — data loading, inference, encoding — all running at different speeds.
- In between workloads, there’s often downtime when jobs are completed, crash, or need to be taken down for debugging. If a really big training run using a few thousand GPUs crashes, all of those GPUs sit idle.
Auxiliary Workers
To make this concrete: imagine we have some encoding tasks that take a few milliseconds and some inference workloads that take a few seconds. It’s like having a one-lane road where race cars are trying to share it with big semi-trucks. The solution is to open up multiple lanes — a slow lane, a fast lane, and maybe more for different types of workloads.
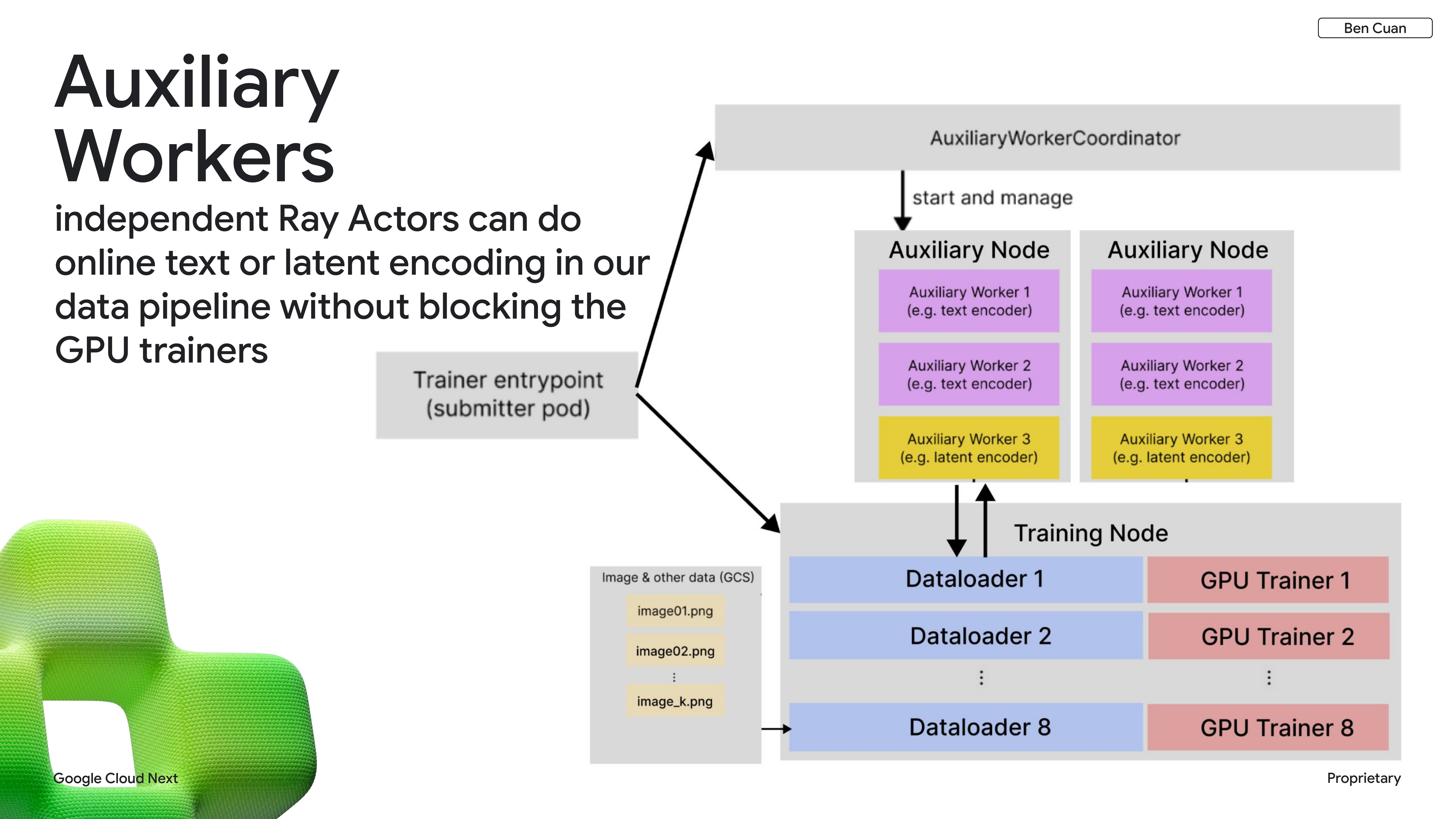
The concrete implementation of this idea is what we call auxiliary workers, which leverages independent Ray actors. We have our main training nodes running the main training loop, and auxiliary workers managed on the side that handle tasks that are temporally slower or faster than the main loop.
We use auxiliary workers for our online reinforcement learning platform. We have separate worker pools that run inference tasks, and when we’re ready to transfer new weights from the main training loop to the inference workers, we use the Ray Object Store. We’re also experimenting with peer-to-peer communication to optimize this further.
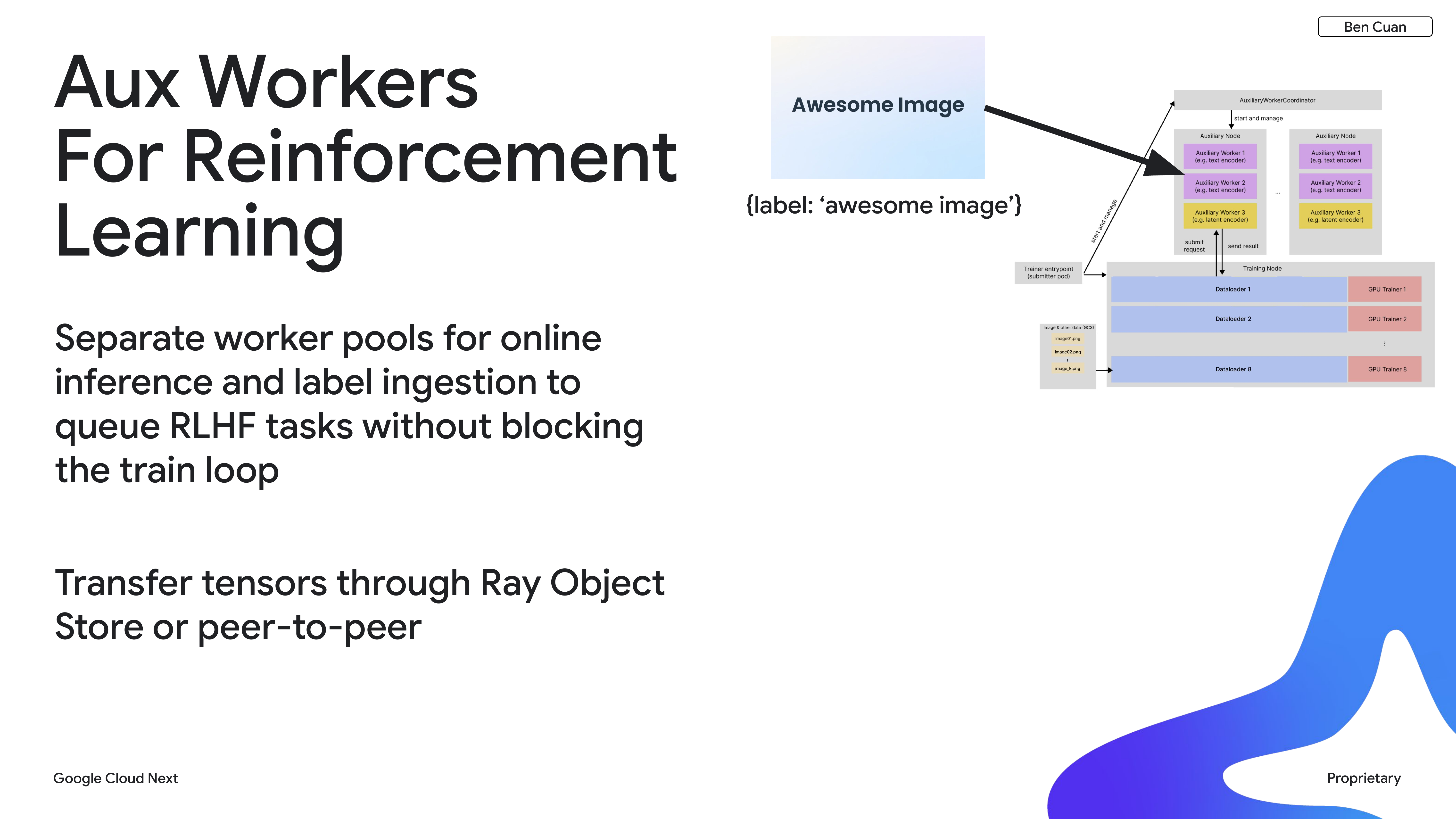
The main benefit is that by packaging many different types of workloads into a single job, we save a lot of developer and researcher time since we don’t have to deal with the overhead of managing separate jobs.
Workload Prioritization with Kueue
How do we keep jobs running 100% of the time while ensuring that our big hero training runs get the resources they need without being blocked by lower-priority tasks? We solve this with preemptable jobs using Kueue.
At Reve, we have two main priority classes. Preemptable jobs are the lower-priority tasks — data classification and similar work where it’s great if they’re running, but we can interrupt them at any time. We set up a large max-worker-scaled preemptable job — in this example, requesting 2,560 GPUs.
If we only have five pods (40 GPUs available) because a big training run is happening, that’s fine. But when that big training run crashes or goes down, we automatically recover all of that capacity and transfer it to the preemptable job, continuing it at larger scale.
With this strategy, we’re able to ensure that a workload is running on any arbitrary node a little more than 90% of the time.
Spatial Heterogeneity
Remote Job Submission with Ray
When we’re dealing with compute fragmented across multiple regions, we could have capacity split between different geographic regions and data centers — mostly because resources are scarce. The problem is that standard distributed training breaks down across multiple data centers, because we expect extremely high throughput and low latency within a single training run, which can really only be achieved with collocated machines.
So how do we take advantage of compute spread across geographic regions? One thing we do on the developer experience side is leverage Ray for remote job submission. Our researchers are used to writing code and developing workloads in our home cluster — say, Cluster A in us-east1. All of their files from NFS, jobs, and development machines are there. But we might have free capacity in Cluster B in europe-west1.

Ray allows us to run a submitter pod in our home cluster that automatically zips up all the code, metadata, and resources needed to run the job, uploads it to the remote region, and communicates across the entire Ray cluster.
Topology-Aware Scheduling
A closely related problem is topology-aware scheduling. With architectures like GB200 NVL72, where 72 GPUs are collocated in one rack with fast interconnect within a rack but slower interconnect between racks, we need to ensure that workers within the same workload are scheduled as close to each other as possible.

There are a few ways to accomplish this:
- GKE labels — we use labels for host, rack, and cluster, and correlate their IDs to schedule workers optimally.
- Kueue-level scheduling — we can specify node labels like
topology.gke.ioand attempt to schedule workers within the same rack.
Future explorations
There are also future explorations that could allow training runs to leverage spatial heterogeneity even more. For example, distributed training algorithms like DiLoCo bake in the assumption of heterogeneity within the actual training loop itself, potentially enabling efficient training across geographically distributed clusters.