

TL;DR
- xAI talk was not that useful.
- Kuberay has a bunch of cool alpha/experimental features.
- Ray Direct Transport is really useful and seems like an obvious drop-in improvement for training.
- SkyRL is cool but it’s only a month old so will be a while before it’s stable or has a reasonable feature set.
1:00: Scaling Image and Video Processing with Ray (xAI)
Grok imagine basics
- xAI image+video generation: T2I, T2V with audio
- Grok imagine video announcement https://x.com/xai/status/1975607901571199086
- Emphasis on dynamic motion data for video training
- The two goals xAi has for their training infra:
- 2x compute should equal 2x throughput.
- minimize human time needing to work with infra. (auto-restart, etc)


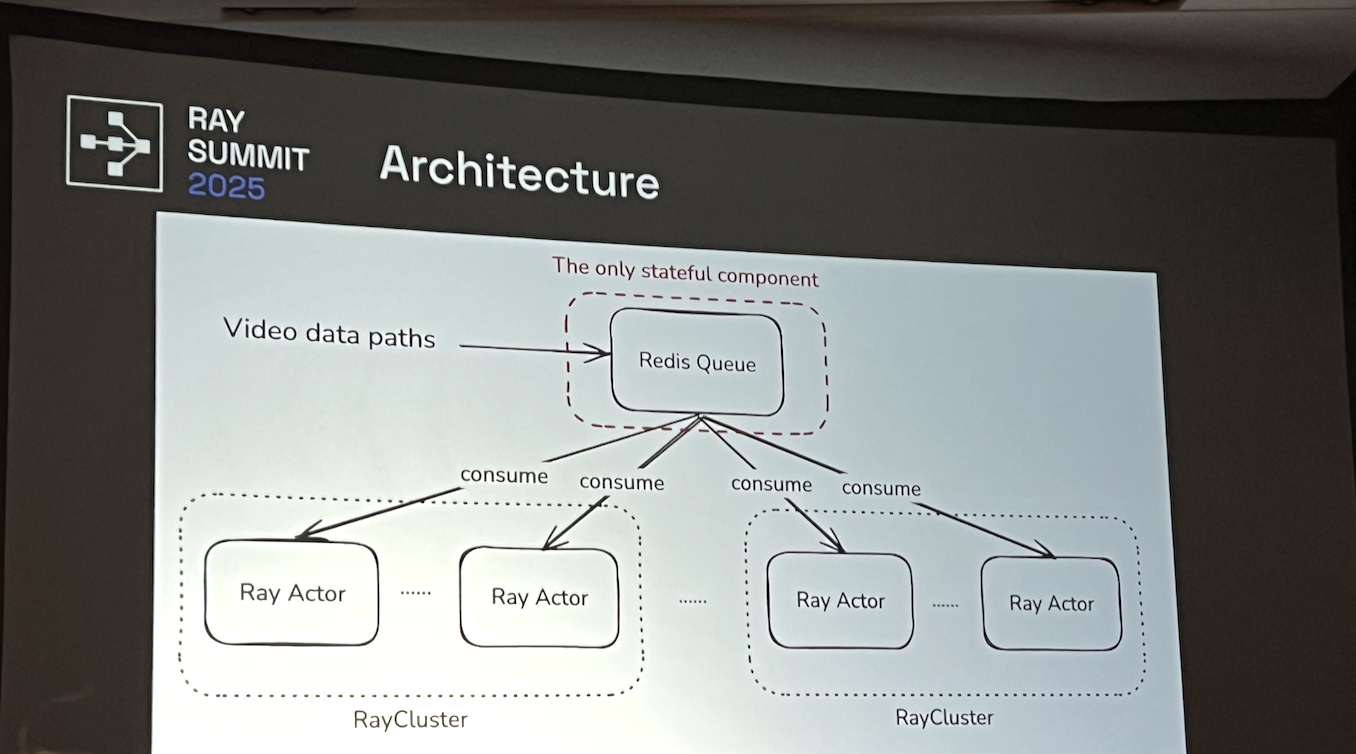
Fault tolerance
 This is for data curation and pretraining mostly.
This is for data curation and pretraining mostly.
- Uses redis queue as single point of failure + only stateful component
- Ray actors should be idempotent
- Redis Reliable Queue
- What happens if the raycluster crashes?
- Health check: gcs ready, raylet, ray dashboard, agent processes
- observability
- ray+kuberay metrics
- k8s events
- Make almost everything preemptible
- they somehow got backoffLimit to work, allegedly. so it is possible.
Ad break: xAi is hiring lol.
Q&A
- How do you dedup video? how is this different from text?
- Video is way more compute and storage heavy
- non-answer.
- What do you do if the raycluster head dies?
- don’t care if jobs fail. auto-restart them.
- store state in shared queue. just resume.
- How to make redis fault-tolerant?
- lots of replicas
- redis clusters
- how to horizontally scale?
- a single raycluster can handle up to 20k actors
- address the bottleneck (sounds like bandwidth)
- what library do they use for video decoding?
- ffmpeg
- decode
- torchcodec
- why rayactors instead of k8s Job?
- better retry behavior
- specify fractional gpu
takeaways
- seems mostly like common sense. they’re obviously not sharing any secret sauce.
1:45: Advancing Kuberay
what is kuberay?

-
k8s operator that sits between k8s clusters and ray core
-
RayClusters have “GCS fault tolerance”. wonder what that means…
- oh. gcs doesn’t mean google cloud storage lol. https://docs.ray.io/en/latest/ray-core/fault_tolerance/gcs.html
-
RayJobs are literally just ephemeral rayclusters
upcoming enhancements
1.5
- Lift resources and labels as structured k8s fields. (could be useful but just seems like refactoring?)

- Atomic multi-host pods
- TPU webhooks
- Treat every replica group as one object to do atomic things like patch/delete
- Rayservice incremental upgrade strategy (NewClusterWithIncrementalUpgrade)
- Rayjob sidecar submission mode (seems useful)
- Launch the job submission container within the ray head pod
- Avoid cross-pod network communication
- Avoids case where RayCluster is waiting for k8s job to be scheduled
- Rayjob DeletionPolicy (very very useful)
- fine grained controls over when to delete workers
- need to enable RayJobDeletionPolicy feature gate
- Keep rayclusters around at a much smaller scale for a long time, which allows for easier debugging
- support for PodGroup from k8s-sigs
ecosystem
- kubectl plugin
- can look into for gkr but seems like more of a QoL thing than a feature
kubectl ray createandkubectl ray scalecommands
- APIServer
- custom authentication+authorization (also very useful for gkr but not critical)
- Dashboard
- view and manage kuberay resources.
- we should get this up
- kuberay now emits prometheus metrics
- this is huge for the program
upcoming
- in-place pod resizing
- fast (2s) vertical scaling of single k8s pod resources
- History server
- access to ray logs, events, and dashboard after termination
- super useful
- basically a better version of gkr-ui
2:30: JIT Embedding
went to this talk since i don’t know how this works and am curious what the differences are between ours and adobe.
- highest meme-to-content ratio of any talk so far.. also speaker was talking at 2x speed. i did my best.
background

- VAE: variational auto-encoder: maps data to latents
- Generate embeddings on-the-fly to produce max flexibility (one training iteration = compute VAE + forward pass + backward pass)
- Alternatively, do offline compute
- VAEs are prone to breaking changes over evolution
- JIT embedding 2x’ed their training speed
architecture
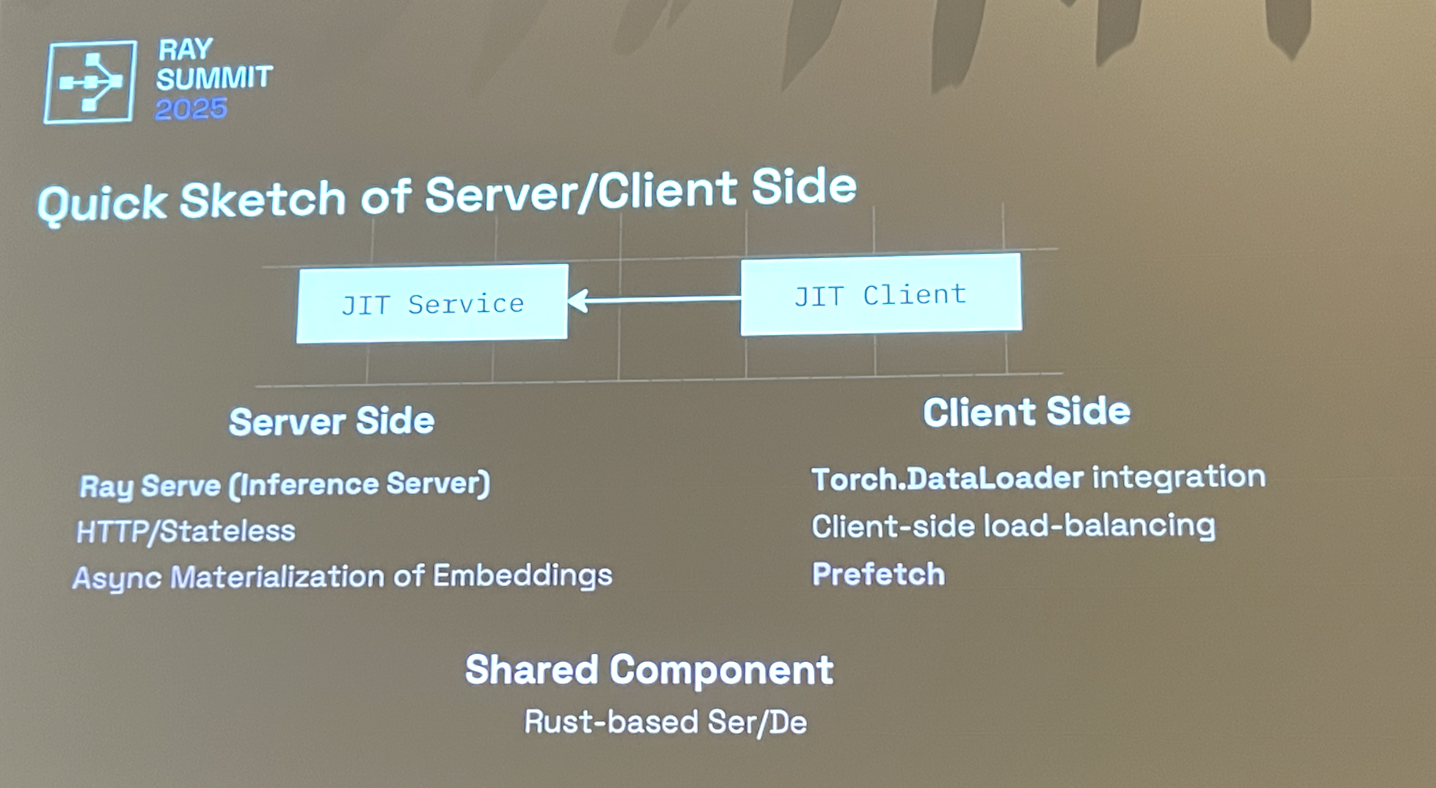
- VAEs are small models, running them on H200s is wasteful.
- Main idea: dedicated service for on-the-fly VAE calculation w/ Ray Serve, deployed on A100s or other cheaper gpus
- Clientside Torch.DataLoader integration
- Rust-based serde
- Batch prefetching
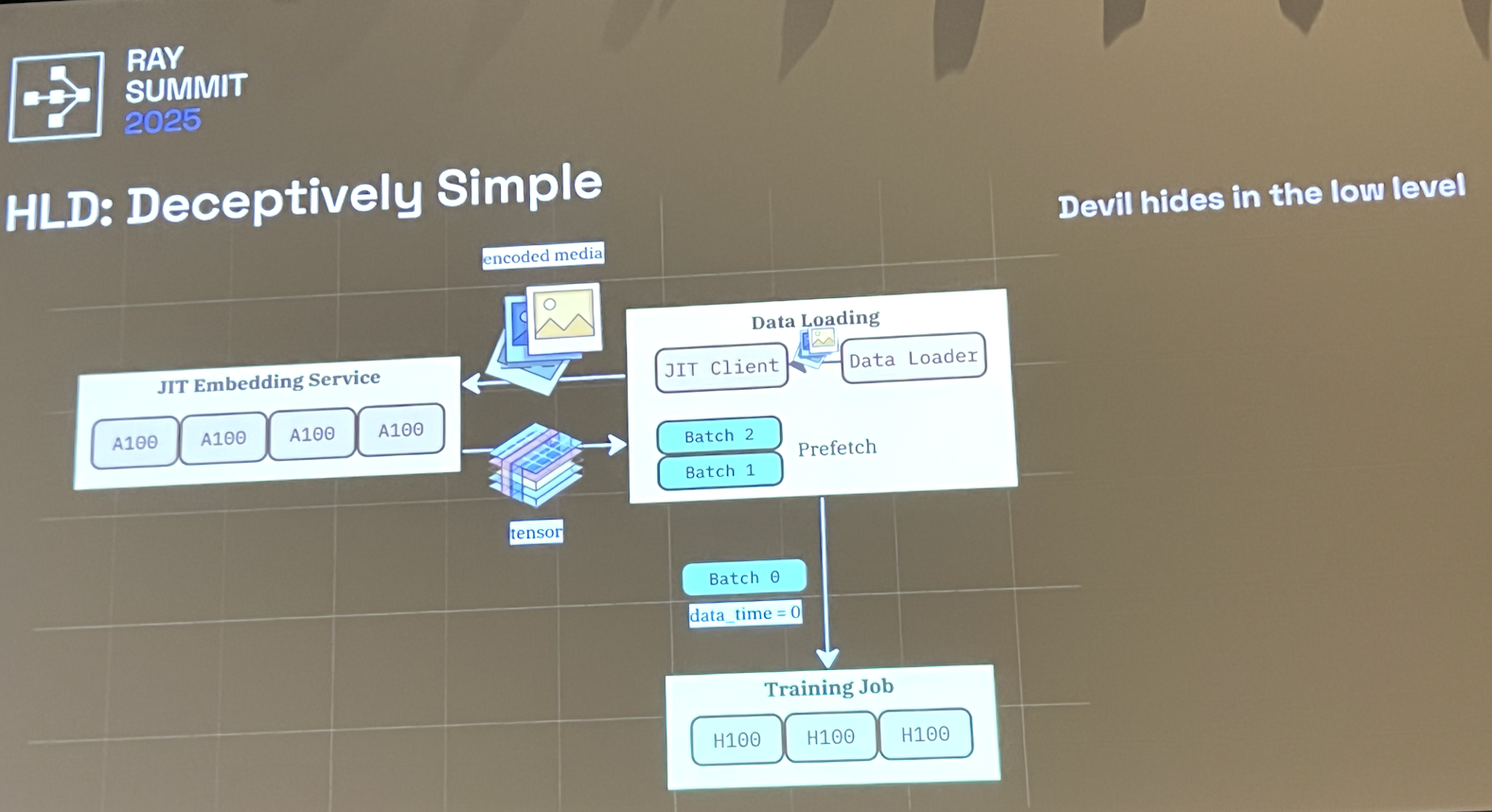
challenges
- Multimodality
- fast rust serialization + lossy codecs for image/video + low-level optimization (MJPEG/zero-copy deserialization/simd)
- Latency
- encodings are not crud + very high latency. model shouldn’t be waiting for seconds for a response
- use order determinism to allow for massive prefetching
- start VAE computation far ahead of time and offload scheduling problems to separate load balancer
- Imbalanced gpu utilization
- how do we run on heterogeneous hardware?
- same solution as latency: rely on LB
- note: we don’t have this problem (yet). all of our training workloads are fairly homogeneous
efficient serde
(note: this section will likely become irrelevant once Direct Transport becomes a thing.)


misc
- adobe is also planning on implementing ray direct transport (see below)
3:15: Ray Direct Transport
The netflix mako talk I wanted to go to instead was crazy oversubscribed (I got there 10mins early and they were already turning ppl back due to capacity). They’re supposed to release a video of it soon so we should watch that.
alpha in ray 2.51.1.
why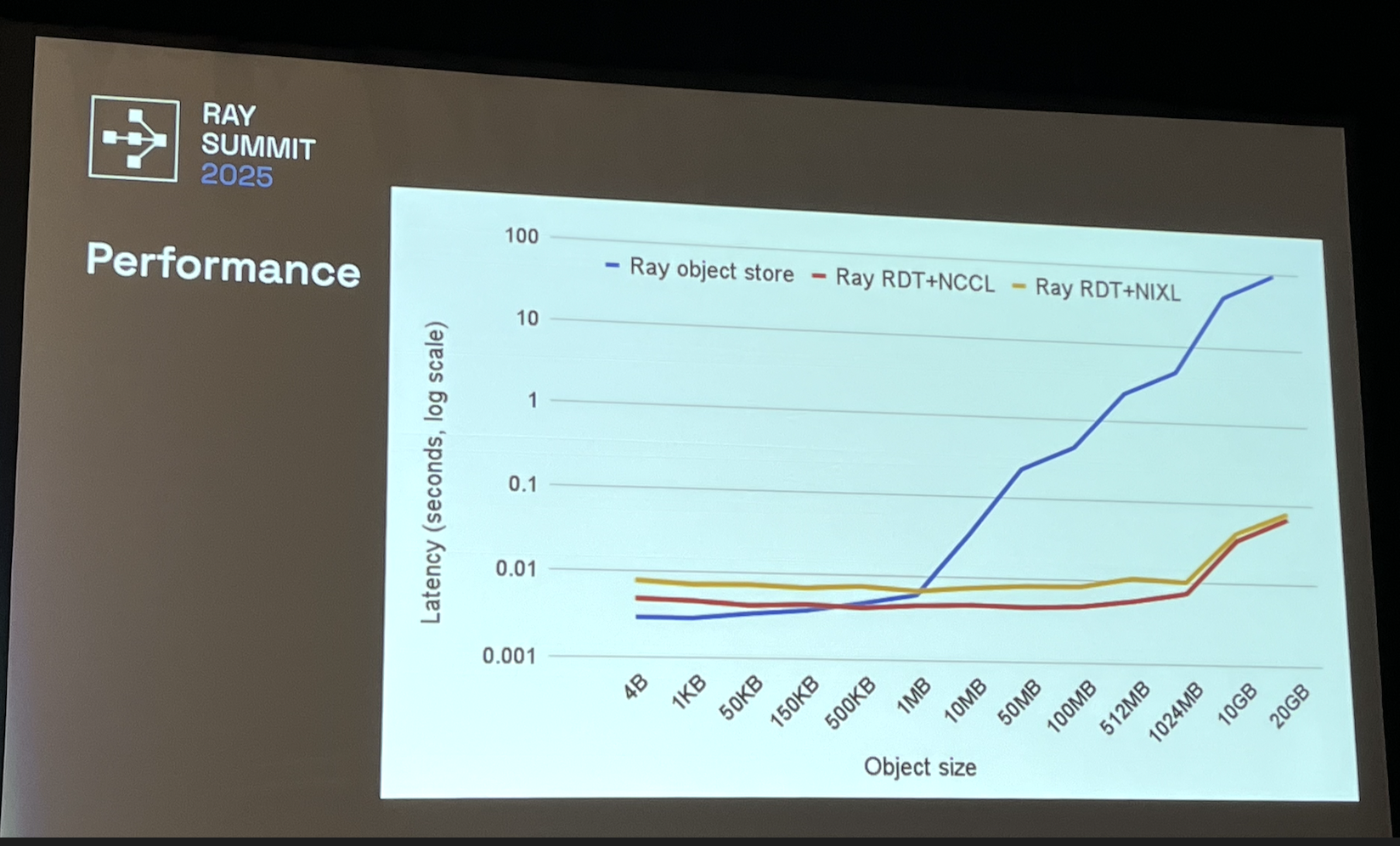
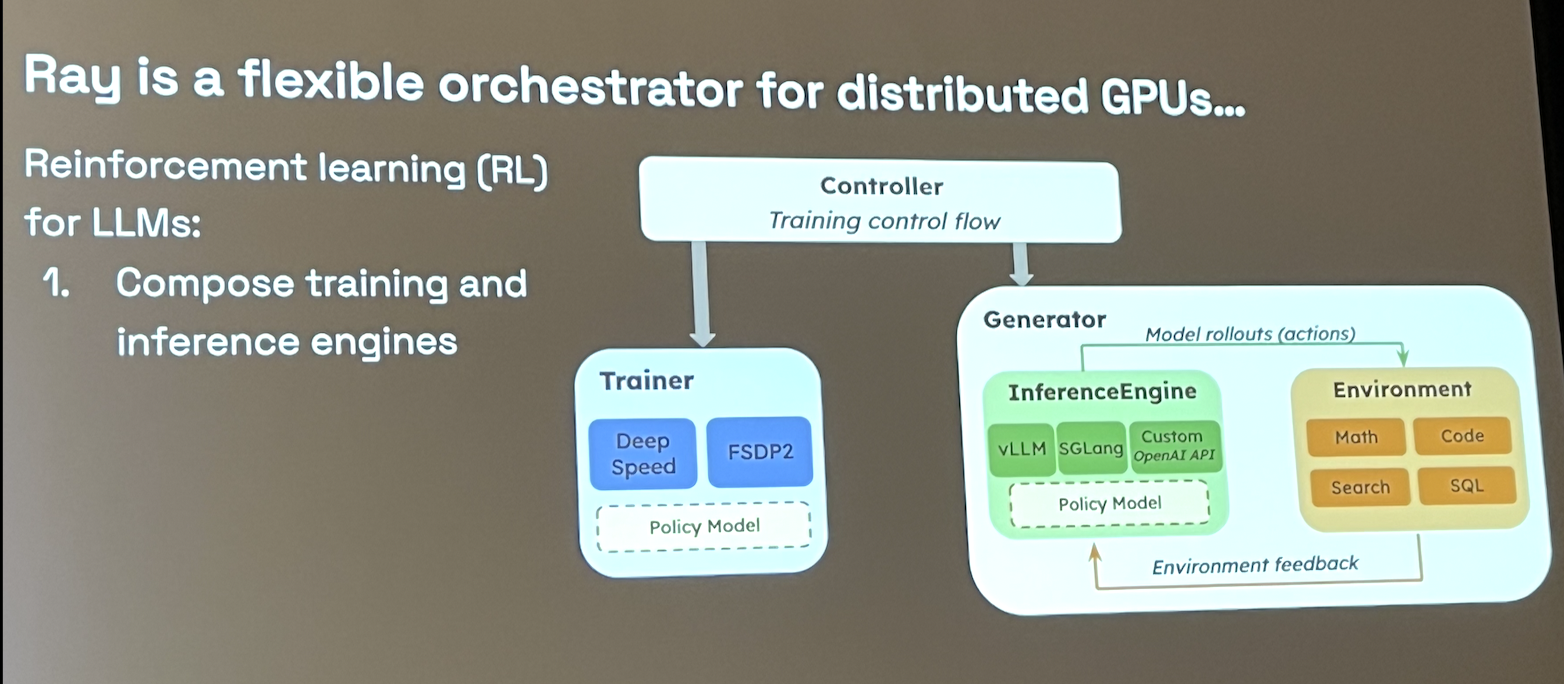
- RL requires composing training with inference (use model to generate training data and feed into itself).
- Main challenge: transfer rollout data and weights between training+inference engines
- Ray’s object store is inefficient for GPU-GPU transfer
- Previously, the Ray object store lived in CPU memory.
- With DT, we’d like to directly use RDMA to perform 1000x faster transfer between GPU memory without needing to go through CPU.
- RDT is built for:
- large objects (TB/s of data over network)
- specialized data transport (RDMA over IB, NVLink)
- Goal: use Ray Core API with a custom data transport so we’re no longer limited to the Ray Object Store.
- Main benefits:
- Keep data unserialized in GPU memory
- Pick your own data transport
- Let ray manage data transfer, GC, failure tolerance
how
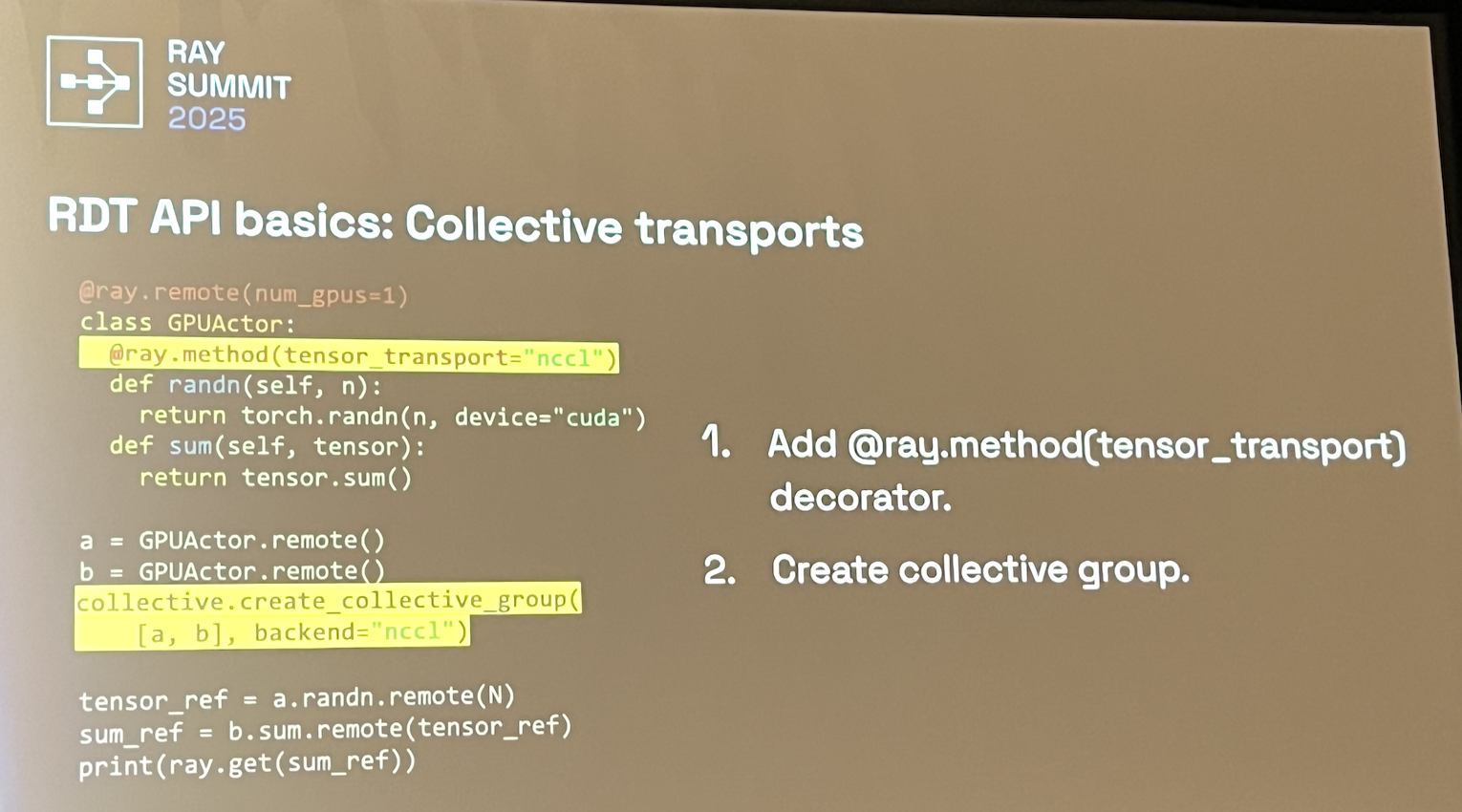
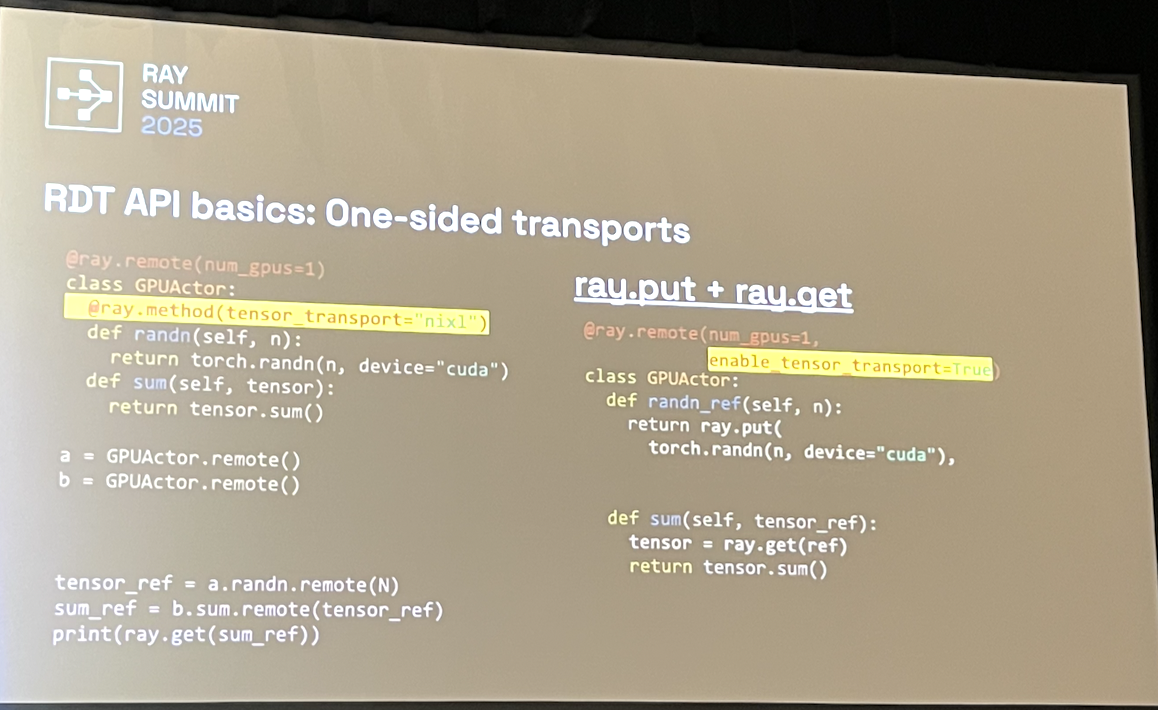
- Gloo, NCCL, and NIXL support
- Supports Ray actors and torch.Tensors
- RDT objects are mutable
- RDT is copy-by-reference and not by-value. RDT automatically handles write concurrency.
- Can either do collective (NCCL) transports or point-to-point (NIXL) via ray.put+ray.get
use cases
- RDMA-based weights sync between trainer and inference engine for RL
future
- verl + skyRL
- asyncio support
- CUDA IPC + BYO transport
Q&A
- differences between single-node and multi-node transport?
- decorators can be specified at runtime to choose a transport based on placement
4:00: SkyRL tx
needed to leave early to make it to next meeting.
what
- enables use of tinker API on our own hardware
- Tinker API basics
- run simple loop on CPU → execute on GPUs (abstract away idea of compute acceleration)
- Four composable core methods:
forward_backward(),optim_step(),sample(),save_state() - Multiplex GPU resources for many individual users
- “let AI researchers ignore infrastructure”
- there should be a shared framework for training infra
- really new project. (1ish month old)
common engine for training and inference
- built on top of jax, pytorch soon.
- “an inference engine that also happens to do backward passes”
- unsure if this will be the ultimate form; maybe using existing training/inference frameworks will end up being more sustainable
architecture
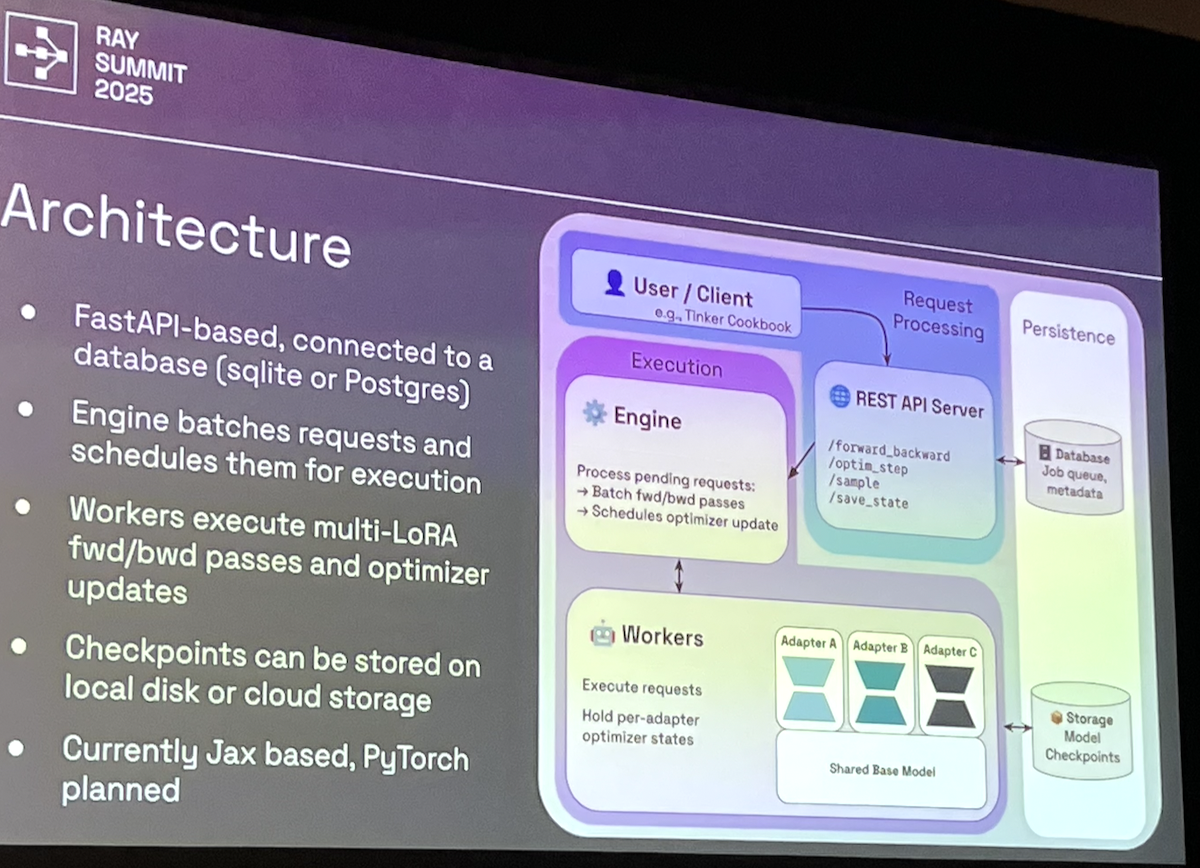
- FastAPI with relational DB
- Batch scheduling (CPU-based engine)
- Performance optimizations
- JIT padding tensors (avoid frequent recompilation)
- KV cache
- Microbatches
- Gradient checkpointing
- Future
- Paged attention
- Prefix cachine
- Custom kernels
- Sharding
- Currently tensor parallel via jax primitives
- Exploring FSDP
